Welcome to my little adventure about writing a machine learning Twitter bot. I’m going to chronicle what I did, where I got my inspiration, and in some parts, how I did it. Why did I decide to create this monstrosity?
Great question..
Once upon a time I stumbled across an article chronicling a machine learning algorithm using the Harry Potter series as input to write it’s own chapter. Enthralled by the pure oddity of what a machine’s understanding of language and creativity turned out to be, I was intrigued to do something similar. But what would I use as input and what would I do with the output? After watching a video series on creating a Twitter bot I put two and two together. I could make a Twitter bot which writes it’s own tweets!
This was followed by another burst of overly enthusiastic thinking, what if I took other user’s tweets as input? Okay cool, but who would ever see these tweets other than myself? How about I take a trending hashtag and use that? Sold.
Now the adventure begins..
First things first, I set up a Twitter developer account, opened up sublime text, created a python file, took a sip of coffee, and installed Tweepy. I then started writing..
The first step was setting up the OAuth handling through Tweepy
First things first, I set up a Twitter developer account, opened up sublime text, created a python file, took a sip of coffee, and installed Tweepy. I then started writing..
The first step was setting up the OAuth handling through Tweepy

Then I needed to take tweets as input. But how am I going to get trending tweets? Luckily Twitter has an endpoint specially built for this reason, sending a simple GET you will get a JSON object filled with all the popular trends from any specified country. I chose the USA as it has the most active Twitter user base.

Now I have the top trending hashtag I want to search with, I needed to get as many tweets as I possibly could. As anyone dealing with machine learning knows, the more data the better. I found that using the standard Twitter search API I would be able to get 15,000 unique tweets at a time, perfect!
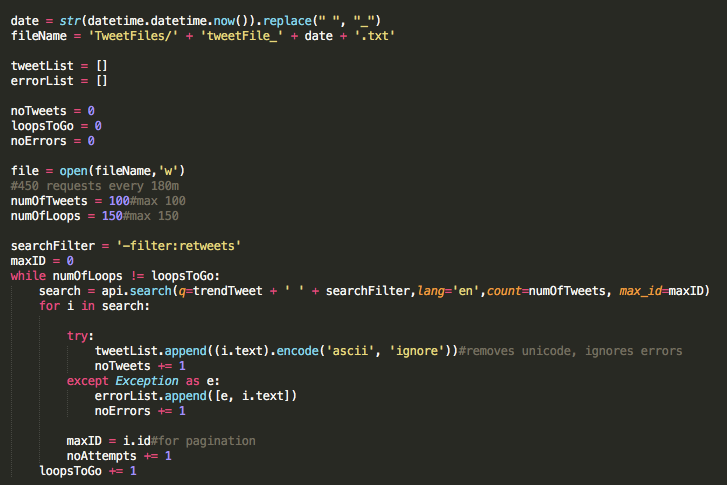
I now have 15,000 tweets to use. It was finally time to train the machine learning algorithm model. Note, the machine learning algorithm i’m using was created by this amazing developer. This was the nerve racking part. Turns out that having more data is awesome, however, when you’re training a machine learning model on your 2015 MacBook Air, it’s slow. This part was massively variable, and completely contingent upon the amount of data scraped. The more data, the longer it took, generally it would take around ~30m to complete training.
Finally, we had success! My Twitter bot wrote it’s first tweet!
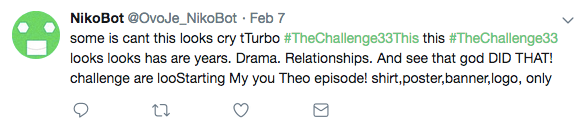
I then set it up to start pushing out a tweet every hour, and things were swell!

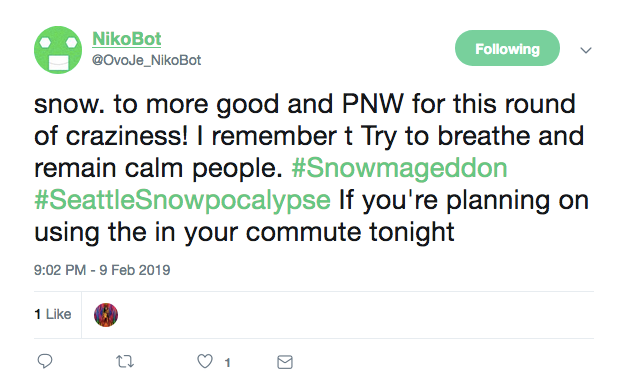

Or so I thought. The longer I left the model to learn, the more issues became glaringly obvious. A lot of tweets came out as unintelligible, which when you’re trying to pass off as a real person, isn’t a great look. So I started to look into the tweets I was using as input.
That was when I found a fatal issue, data quality.
I started to investigate the tweets which were being used as input to see what the model was learning from. And I came to a few conclusions.
Tweets which were being used to train the model had a variety of syntax and grammatical issues. This would be fine if the issues were consistent across user tweets. However, the inconsistency provided limited the learning process by adding more novel situations into the training stage than desired. When it comes to machine learning, data consistency is key. You ideally want a lot of training data, and data which doesn’t vary as massively as this did.
With all that being said, I still tried to provide a solution. My solution was to add a dictionary check when reading the tweet. It was simple and elegant, if the words in the tweet were all found inside the English dictionary, the tweet was valid! This should eliminate spelling mistakes as an issue.
Problem solved. Or so I thought…
What did this actually end up doing? It cut down the number of ‘valid’ tweets from 15,000 down to less than 1,000. And the tweets that passed my vetting could still have grammatical issues.
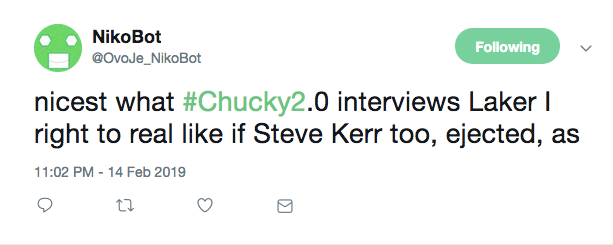
At this point I felt like the project had come to a natural end. I had worked on it and thought about it for months, and every solution I had required more work than I was willing to give.
Conclusion
All of this brought me to my final conclusion. Twitter is the wrong platform for this model to learn from. The data consistency issues were too debilitating to facilitate a reliable learning process. Furthermore, due to the character limit on tweets (280 chars), users have adapted by using shorthand to get a point across within the limit. Thus a social media platform which promoted better English would be ideal. Unfortunately no other social media platform has quite the same mix of being massively active hives of content, a strong developer API and a trend system as a core part of the experience.
At least I got to learn a bunch about machine learning and the Twitter API.
Months later I became nostalgic about the project, and decided to use the data which I had scraped to create a bunch of unique statistics. Here are some of them.
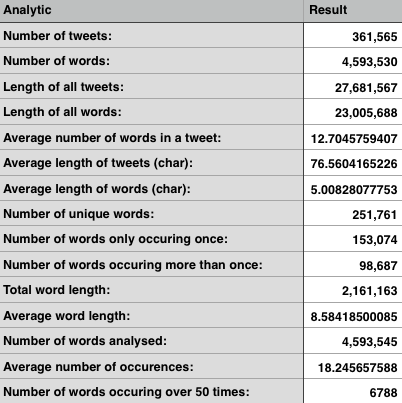
Feel free to check out the finished bot, and see it live tweet if I get it up and running again.